

Grok Code Fast 1是什么?
Grok Code Fast 1是埃隆·马斯克旗下xAI公司在2025年8月29日推出的一款颠覆AI编程领域的模型。这款以“速度”为核心竞争力的模型,凭借每秒190 token的极速响应、256K超长上下文窗口以及极具侵略性的定价策略,在发布后迅速引爆开发者社区。从GitHub Copilot到Cursor,七大主流开发平台同步开放限时免费试用,一场关于AI编程工具的“效率革命”就此拉开帷幕。
一、技术架构:
Grok Code Fast 1的诞生,源于xAI对传统AI编程工具痛点的*洞察。传统模型在IDE中调用终端、编辑文件或执行复杂任务时,常因架构设计缺陷导致卡顿,而Grok Code Fast 1通过全新轻量级架构彻底重构了这*程:
预训练与微调双优化模型以海量编程语料库为基础进行预训练,涵盖TypeScript、Python、Java、Rust、C++、Go等主流语言代码库。随后,通过真实*中的Pull Request、开发任务数据集进行微调,使其能*理解开发者意图,甚至在无监督状态下完成从项目搭建到Bug修复的全流程。
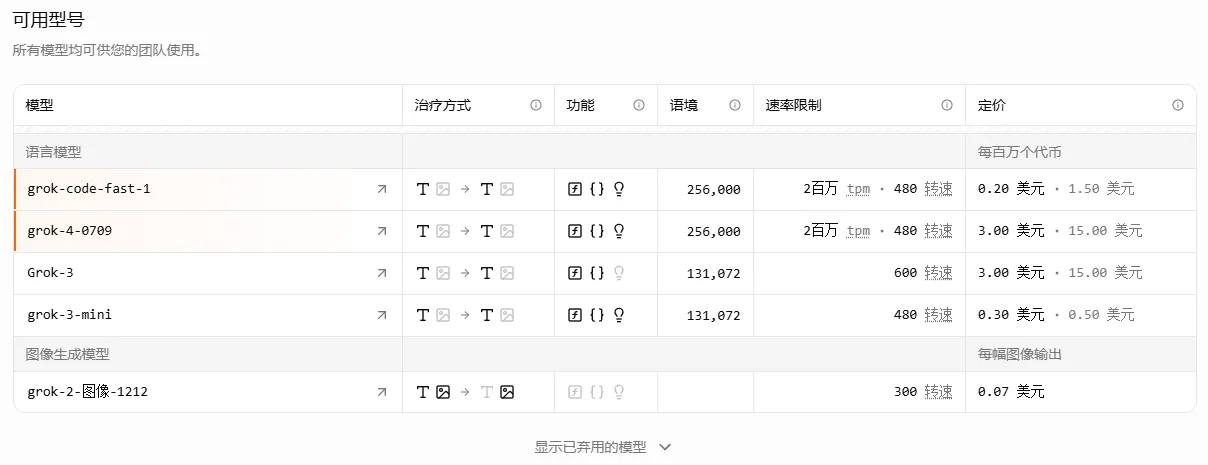
256K上下文窗口与工具链集成支持256K tokens的上下文窗口,可覆盖大多数单体代码库的完整逻辑。更关键的是,它深度集成grep、终端操作、文件编辑等开发者常用工具,能在IDE内自主调用这些工具完成多步骤任务。例如,用户仅需输入“为当前项目生成单元测试并配置Docker容器”,模型即可自动完成代码生成、测试框架安装和容器化部署。
推理加速与缓存技术xAI自研的推理加速引擎使模型在流式响应中展现“思考轨迹”,用户可实时观察其推理过程。配合超过90%的提示缓存命中率,重复计算量减少90%以上,确保在处理大型代码库时仍能保持毫秒级响应。
二、性能表现:
在SWE-Bench-Verified基准测试中,Grok Code Fast 1以70.8%的问题解决率逼近GPT-5和Claude Opus,但成本仅为后者的1/10。这一成绩源于三大技术优势:
极速响应能力每秒190 token的生成速度,远超GPT-5的60 token/秒和Claude 4的80 token/秒。实测中,模型可在用户读完首段思考轨迹前完成数十次工具调用,例如在制作Pygame小游戏时,从指令输入到交互式界面生成仅需3秒。
多语言与多任务支持除主流编程语言外,模型还擅长UI设计、游戏模拟器开发等跨领域任务。开发者通过简单提示即可生成时间晶体动态效果、随机多媒体交互界面等复杂功能,且代码质量达到生产级标准。
代理式编程范式与传统代码补全工具不同,Grok Code Fast 1能像真人程序员一样规划任务流。例如,在修复代码库中的跨文件错误时,它会先分析依赖关系图,再分批次修改并自动运行测试套件,整个过程无需人工干预。
三、模型定价:
xAI的商业化路径堪称“颠覆性”:
限时免费开放发布首周,Grok Code Fast 1在GitHub Copilot、Cursor、Cline等七大平台提供免费试用。其中,GitHub Copilot用户可体验至9月2日,Cursor用户享有一周免费权限,Windsurf的Pro和Teams用户则获得无限制使用资格。
超低定价策略正式商用后,模型采用按量计费模式:输入token:0.20美元/百万输出token:1.50美元/百万缓存输入token:0.02美元/百万这一价格仅为GPT-5的1/6、Claude 4的1/5,甚至低于Qwen3-Coder等开源模型。
生态协同战略xAI明确Grok Code Fast 1与Grok 4的定位差异:前者专注敏捷编码,后者深耕深度推理。两者通过API互通,开发者可在一个工作流中同时调用Grok 4进行架构设计,再用Grok Code Fast 1实现细节编码。此外,xAI承诺半年后开源Grok 3,进一步降低技术门槛。
四、应用场景:
高频轻量任务模型在代码补全、片段生成等场景中响应极快,尤其适合快速迭代开发。例如,开发者在编写React组件时,模型可实时建议最佳实践代码,并自动生成配套的TypeScript类型定义。
自动化工作流支持多步骤自动化任务,如:批量生成API文档并配置Swagger根据数据库Schema自动生成CRUD代码将Jupyter Notebook转换为可部署的Python模块某开发者利用Grok Code Fast 1在24小时内完成了从需求分析到容器化部署的全流程,开发效率提升300%。
跨文件重构256K上下文窗口使其能处理中等规模代码库的重构需求。例如,在将JavaScript项目迁移至TypeScript时,模型可自动识别类型定义、修改依赖关系并修复类型错误,准确率超过92%。
五、局限性与未来规划
尽管表现卓越,Grok Code Fast 1仍存在两大短板:
超长文档输出受限:单次输出最大支持4K tokens,难以生成完整技术白皮书或复杂算法论文。
架构设计深度不足:在分布式系统、高并发架构等场景中,其建议质量仍落后于Claude 4和GPT-5。
xAI已公布路线图:
2025年Q4:支持多模态输入(如根据设计图生成前端代码)
2026年Q1:引入并行工具调用,将多步骤任务处理速度提升5倍
2026年Q2:扩展上下文窗口至1M tokens,覆盖企业级代码库



